GPT-4隐藏了参数规模等指标,更未提及其碳足迹
发布时间:2023-04-06 11:01:59 【来源:虎嗅网】
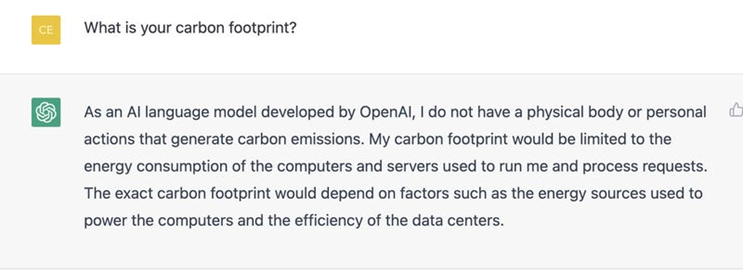
它马上甩锅:“作为OpenAI开发的AI语言模型,我没有产生碳排放的身体或个人行为。”
然后振振有词地说:“是那些运行我的计算机和服务器干的。”
追踪碳足迹
谷歌发了一篇论文,建议这么算碳足迹:(训练阶段的电力消耗 + 推理阶段的查询次数×单次推理的电力消耗) × 数据中心单位电力消耗的二氧化碳排放量。也就是说,它消耗的电量,以及消耗的电的碳强度。
前者的影响因素很多。不同的模型、不同的算法、参数规模大小、处理器的数量和类型、处理器的算力与功率、数据中心的电源使用效率(PUE)等。有些指标可以测得,有些则需要推算。
后者则在很大程度上取决于电力的生产方式,风电、光伏、水电这些清洁电力往往有很强的地域性,并且不同时间不同季节发电出力也有区别。电网里输送的电力,既然包括煤电这些高碳排放的电力,也包括无碳排放的清洁电力,所以电网都有一定的平均碳强度。
大模型的碳排放可以分为训练与推理两大阶段,谷歌却选择只研究训练阶段。在谷歌以往三年的机器学习的能耗占比中,训练用了40%,推理用了60%。
AI初创公司Hugging Face前进了一大步。它发表的论文关注了大模型全生命周期的碳排放,包括了算力硬件产生的碳排放,但不包括原材料阶段与设备报废阶段。该公司的大型语言模型BLOOM,训练产生了25吨的二氧化碳,但全生命周期的碳排放量则翻了一番。
谷歌自夸的底气
谷歌认为学界低估了业界的努力,高估了大模型的实际碳排放量。
2021年和2022年,谷歌连发两篇论文,为行业正名,称尽管算力需求持续增长,但自己通过对模型(Model)、机器(Machine)、机械化(Mechanization)、位置(Map)的优化,大模型在谷歌整体碳足迹中的占比没有增加,稳定在10%~15%的区间。
谷歌硬凑了4个M,用大白话翻译一下,就是稀疏型模型的能耗比密集型更低,TPU等专用芯片的能耗比GPU更低,自动化管理和优化运算资源,大规模用上绿电的数据中心碳排放更低。
谷歌评估了五种自然语言模型的碳排放量,分别是T5、Meena、GShard、Switch Transformer和GPT-3。前四个都是谷歌的模型。GPT-3来自OpenAI与微软,谷歌暗暗踩了同行一脚。
GShard表现最佳。GShard的参数规模高达6190 亿,是GPT-3的1750亿的3.5倍左右,但消耗的能源反倒只是后者的1/ 53,净碳排放量更是只有后者的1/127。
谷歌解释称,这得益于GShard的稀疏型算法,它可以在不牺牲准确性的前提下,消耗更少的能源;而密集型算法中,大多数神经元都会被激活,消耗的能源大量增加。此外,模型越来越快,设备使用时间越来越短。2021年,谷歌发表第一篇论文时最新的模型,相比四年前的Transformer,在回答质量基本不变的前提下,速度提升了4.2倍。
谷歌还称,与别人家都在用的GPU相比,自家的TPU的性能功耗比在实战中更胜一筹。理论上,在V100上运行GPT-3的性能功耗比,要比在TPU v3上运行谷歌的模型好1.5倍;但实际测量下来正好相反,TPU v3平均是V100的2倍。V100是论文发表时主流的人工智能算力硬件。
云端计算很重要。云计算通过大规模的数据中心,提高电力使用效率,避免浪费闲置的算力。云在哪里计算更重要。云计算允许客户选择清洁能源最密集的区域,这才是谷歌最大的优势。
谷歌还画了一张图,为自己打分,证明自己一直在进步。但这幅图透露了谷歌的模型碳排放量低的最大秘密,正在于绿色能源的使用。如果以2017年的表现为基准,经过四年的持续改进,谷歌在能源消耗上的得分提升了83倍,在碳排放量上的得分,提升了747倍。

沉默的GPT
并不是只有谷歌踩了GPT-3一脚。GPT历代大模型已经成为大家对比的标杆。而且,它的碳排放量数据,几乎都来自这些竞争对手的论文。
Hugging Face说,我家的大模型BLOOM,参数规模1760亿,OpenAI家的大模型GPT-3,参数规模1750亿,大家不相上下,但训练BLOOM的碳排放量只是GPT-3的1/20。
Meta的论文,把BLOOM和GPT-3都列上了。训练四个不同参数规模的LLaMA大模型,碳排放量都要低于BLOOM,也就低于GPT-3。
还有好事者定期给ChatGPT算一笔碳账。他在自己的专栏Towards Data Science写道,参考规模类似的BLOOM执行推理的能耗(每次查询 0.00396 千瓦时),1月份在用户进行了5.9 亿次访问后,ChatGPT消耗的电力在110 万至 2300 万千瓦时之间。
上下限相差巨大,是因为他做了两大假设,每个假设分三档,共9个场景:ChatGPT 每次查询的耗电量,可能因为查询需求更密集而降低;每次访问的查询次数有高有低。
他自己也不满意这个计算。3月,他读到了另一篇估算ChatGPT推理的货币成本的文章。那篇文章假定,ChatGPT 每天有 1300 万用户,每人发出 15 个请求,这需要28936 个A100的算力。
他顺着这个思路估算,如果 ChatGPT 每天有 1300 万用户,每人发出 15 个请求,ChatGPT的每月用电量为 2316万千瓦时;如果需要28,936个A100,大概需要电力416万千瓦时。两个数据基本落在此前估算区间附近,他相信BLOOM碳足迹的论文、他的ChatGPT能耗推算,以及另一篇ChatGPT推理成本估算都有可取之处。
但他没有继续估算ChatGPT的碳足迹。因为随着算力需求的膨胀,ChatGPT 很可能需要调用部署在多地的数据中心的算力。但不同数据中心的电源使用效率不同,也就是同样算力需求,效率低的数据中心消耗的电力更多;此外,不同数据中心所在电网的平均碳强度也不同。按谷歌的论文,训练GPT-3,耗能1287兆瓦时,排放二氧化碳550吨。
透明、绿色
GPT的未来,正在遭遇外界夸大风险的反噬,但人们同样呼吁GPT增加透明度,包括公开碳足迹的信息。
GPT-4隐藏了参数规模等指标,更未提及其碳足迹。媒体批评大模型正消耗的能源,已经堪比加密货币挖矿。
全球科技巨头都在陆续承诺碳中和。微软承诺2030年实现负碳排放。谷歌则承诺到2030年实现所有数据中心7X24使用绿电。尽管科技巨头是全球最大的绿电采购者,但随着它们纷纷加快AI化,展开大模型的“军备竞赛”,产生的碳排放受到更多关注。
OpenAI暂未公开宣布有关减排的具体细节和计划。但似乎把锅甩给了微软,我只负责智能,微软负责减碳。
附:AI企业对旗下大模型碳足迹的研究论文的标题
Meta
Sustainable AI: Environmental Implications, Challenges and Opportunities,2022年1月
LLaMA: Open and Efficient Foundation Language Models,2023年2月
谷歌
Carbon Emissions and Large Neural Network Training,2021年4月
The Carbon Footprint of Machine Learning Training Will Plateau, Then Shrink,2022年2月






GPT-4隐藏了参数规模等指标,更未提及其碳足迹
4月6日讯:有好事者问ChatGPT,说说你的碳足迹吧。 它马上甩锅:作为OpenAI开发的AI语言模型,我没有产生碳排放的身体或个人行为。 ...
通胀放缓,但不足以让欧央行暂缓加息
4月6日讯:在整个欧洲,各国通胀呈现了一幅复杂的画面,有的国家通胀仍然居高不下,有的国家则把通胀控制在了较低的水平。 在欧洲各 ...
说明了日本动画在国内的普及程度在变化,谁决定了日漫IP的票房
4月6日讯:上映12天,票房5 86亿。 这是截至发稿前,《铃芽之旅》在内地的战果,打破了由新海诚另一部电影《你的名字。》保持的日本 ...
8th Street联名系列国内首次发售
4月4日讯:近日风靡的王炸组合KITH X Clarks Originals 三方联名鞋款在知名设计师兼 KITH 主理人 Ronnie Fieg的独特审美下,极 ...
特步361度全力向上,安踏李宁叫板耐克阿迪
4月4日讯:阿迪达斯和耐克的失速还在继续。 3月8日,阿迪达斯发布2022年第四季度业绩报告,营收52 1亿欧元,仅同比增长1 3%,剔除汇 ...
一眼心动重庆城!重庆全民赏花季拉开序幕,十里春色描绘山城之美
春路雨添花,花动一山春色。三月伊始,在记者的跟踪报道中,笔者发现三月的重庆城,已经包裹在花香馥郁的氛围之中。作为市民赏花的好时 ...

- Copyright © 2013-2020 All rights reserved
- 联系我们